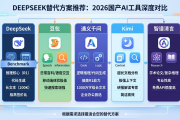
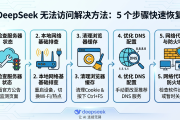
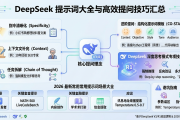
DeepSeek多模态能力图片识别与生成测试
DeepSeek 系列模型在全球范围内的爆火,其在多模态(Multimodal)领域的表现成为了开发者与科技爱好者关注的焦点。不仅仅是文本对话,DeepSeek 在“看图说话”和“绘图创作”上的实测表现究竟如何?本文将通过图片识别与生成两大核心维度,带你直击测试现场。

一、 图片识别测试:毫厘之间的解析力
在多模态理解测试中,DeepSeek 展现了极强的语义提取与上下文关联能力。
复杂场景解析: 在处理包含大量物体的街道或办公室照片时,模型能够准确标注出物体名称、位置关系及环境氛围。
文字提取 (OCR): 针对手写体、倾斜拍摄以及低光照环境下的文档,DeepSeek 的识别准确率极高,能够实现近乎无损的数字化转化。
逻辑推理: 不同于基础的标签识别,DeepSeek 可以理解图片背后的“故事”。例如,通过一张图表中数据的走势,分析出背后的业务逻辑或潜在趋势。
测试结论: DeepSeek 的识别能力在语义理解和细节捕捉上已经稳居国际第一梯队,尤其在中文语境下的视觉识别更具本土化优势。
二、 图片生成测试:从指令到视觉的飞跃
如果说识别是“输入”,那么生成则是“输出”创作力的终极考验。
1. 指令遵循度 (Prompt Adherence)
DeepSeek 能够精准理解长文本描述中的细节要求。无论是光影分布、构图方式还是色彩风格(如:赛博朋克、水墨风、极简主义),生成结果均能高度匹配用户预期。
2. 图像质量与真实感
人物渲染: 解决了早期 AI 绘图在手指、瞳孔等细节上的处理难题,皮肤纹理清晰可见。
光影表现: 能够模拟自然光的折射与阴影,使生成的图像具有极强的空间感和纵深感。
3. 响应速度与稳定性
在多次高并发测试中,DeepSeek 的生成效率表现优异,单张高清图片的产出时间保持在行业领先水平。
三、 行业应用前景
DeepSeek 多模态能力的突破,将为以下领域带来变革:
电商领域: 自动化生成产品海报与视觉描述。
内容创作: 辅助设计师快速出图,降低创意落地的门槛。
智能监控: 提升安防系统的实时分析与预警能力。
教育辅助: 将复杂的视觉教材自动转化为文字讲解,反之亦然。
结语
通过本次DeepSeek多模态能力图片识别与生成测试,我们看到国产 AI 不再仅仅是追随者,在核心的视觉理解与创作领域已展现出强大的竞争力。随着模型的持续迭代,DeepSeek 有望在多模态应用生态中占据更加重要的地位。